Fyrr eða síðar standa allir sem oft vinna með skrifstofuforrit fyrir dæmigerðu verkefni - að skanna texta úr bók, tímariti, dagblaði, bara bæklingum og þýða síðan þessar myndir á textasnið, til dæmis í Word skjal.
Til að gera þetta þarftu skanna og sérstakt forrit til að þekkja texta. Í þessari grein verður fjallað um ókeypis hliðstæðu FineReader -Bollalaga (um viðurkenningu í FineReader - sjá þessa grein).
Byrjum ...
Efnisyfirlit
- 1. Aðgerðir CuneiForm forritsins, eiginleikar
- 2. Dæmi um texta viðurkenningu
- 3. Viðurkenningu lotutexta
- 4. Ályktanir
1. Aðgerðir CuneiForm forritsins, eiginleikar
 Bollalaga
Bollalaga
Þú getur halað því niður af vefsíðu þróunaraðila: //cognitiveforms.com/
Opið hugbúnað fyrir opinn uppspretta texta. Að auki virkar það í öllum útgáfum Windows: XP, Vista, 7, 8, sem þóknast. Plús bættu við fullri þýðingu Rússlands á forritinu!
Kostir:
- texta viðurkenningu á 20 vinsælustu tungumálum heims (enska og rússneska er í sjálfu sér innifalin í þessu númeri);
- Gífurlegur stuðningur við ýmis prent letur;
- athugaðu orðabókina á viðurkenndum texta;
- hæfileikinn til að vista niðurstöður á ýmsa vegu;
- varðveisla uppbyggingar skjalsins;
- Mikill stuðningur og borð viðurkenning.
Gallar:
- styður ekki of stór skjöl og skrár (meira en 400 dpi);
- Styður ekki beint tilteknar tegundir skanna (það er ekki mikið mál, sérstakt skannarforrit fylgir skannabílstjórunum);
- hönnunin skín ekki (en hver þarfnast hennar ef forritið leysir vandann að fullu).
2. Dæmi um texta viðurkenningu
Við gerum ráð fyrir að þú hafir þegar fengið nauðsynlegar myndir til viðurkenningar (skannaðar þar, eða halað niður bók á pdf / djvu sniði á Netinu og fjarlægt nauðsynlegar myndir af þeim. Sjáðu til þess hvernig þú getur gert þetta).
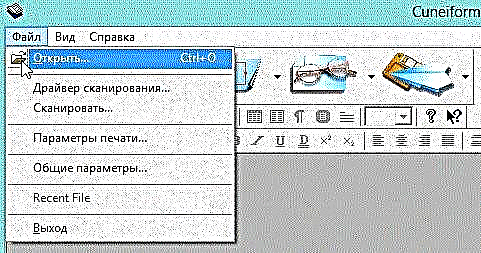
1) Opnaðu myndina sem óskað er eftir í CuineForm forritinu (skjal / opið eða "Cntrl + O").
2) Til að hefja viðurkenningu - verður þú fyrst að velja ýmis svæði: texta, myndir, töflur osfrv. Í Cuneiform forritinu er þetta ekki aðeins hægt handvirkt, heldur einnig sjálfkrafa! Til að gera þetta, smelltu á hnappinn „skipulag“ efst á glugganum.

3) Eftir 10-15 sekúndur. Forritið mun sjálfkrafa varpa ljósi á öll svæði með mismunandi litum. Til dæmis er textasvæði auðkennt með bláu. Við the vegur, hún varpaði ljósi á öll svið rétt og nokkuð fljótt. Heiðarlega, ég bjóst ekki við svona skjótum og réttum viðbrögðum frá henni ...

4) Fyrir þá sem ekki treysta sjálfvirka skipulaginu geturðu notað handbók. Til að gera þetta er tækjastika (sjá myndina hér að neðan), þökk sé þeim sem þú getur valið: texti, tafla, mynd. Færa, stækka / minnka upphafsmyndina, klippa brúnirnar. Almennt gott sett.

5) Eftir að öll svæði hafa verið merkt getum við haldið áfram viðurkenningu. Til að gera þetta, smelltu einfaldlega á hnappinn með sama nafni, eins og á myndinni hér að neðan.

6) Bókstaflega á 10-20 sekúndum. Þú munt sjá skjal í Microsoft Word með viðurkenndum texta. Athyglisvert er að auðvitað voru villur í textanum fyrir þetta dæmi, en það eru mjög fáir af þeim! Þar að auki, miðað við í hvaða unprepossessing gæði uppsprettuefnið var - mynd.
Hraðinn og gæði eru alveg sambærileg við FineReader!

3. Viðurkenningu lotutexta
Þessi forritsaðgerð getur komið sér vel þegar þú þarft að þekkja ekki eina mynd heldur nokkrar í einu. Flýtileiðin fyrir upphafsgreiningar er venjulega falin í upphafsvalmyndinni.
1) Eftir að forritið hefur verið opnað þarftu að búa til nýjan pakka eða opna áður vistaðan pakka. Í dæminu okkar, búðu til nýjan.

2) Í næsta skrefi gefum við því nafn, helst það sem minnir á það sem geymt er í því sex mánuðum síðar.

3) Næst skaltu velja skjalatungumálið (rússnesk-ensku), tilgreina hvort það séu myndir og töflur í skannaða efninu.

4) Nú þarftu að tilgreina möppuna sem skrárnar fyrir viðurkenningu eru í. Við the vegur, það sem er áhugavert, forritið sjálft finnur allar myndir og aðrar grafískar skrár sem það getur þekkt og bætt þeim við verkefnið. Þú verður bara að fjarlægja viðbótina.

5) Næsta skref er ekki mikilvægt - veldu hvað á að gera með frumskrárnar, eftir viðurkenningu. Ég mæli með að þú veljir gátreitinn „gera ekkert“.

6) Eftir er að velja það snið sem viðurkennda skjalið verður vistað í. Það eru nokkrir möguleikar:
- rtf - skjal úr orðsskjali, opnað af öllum vinsælum skrifstofum (þ.mt ókeypis skrifstofum, tengill á forrit);
- txt - textasnið, þú getur vistað aðeins texta í því, myndir og töflur geta ekki verið;
- htm - stikla síðu, hentug ef þú skannar og þekkir skrár fyrir vefinn. Við munum velja það í dæminu okkar.

7) Eftir að hafa smellt á hnappinn „Ljúka“ byrjar ferlið við vinnslu verkefnisins.

8) Forritið virkar ansi hratt. Eftir viðurkenningu birtist flipi með HTML skrám fyrir framan þig. Ef þú smellir á slíka skrá byrjar vafrinn þar sem þú getur séð árangurinn. Við the vegur, er hægt að vista pakkann til frekari vinnu með það.

9) Eins og þú sérð, árangurinn verkið er mjög áhrifamikið. Forritið þekkti myndina auðveldlega og fyrir neðan hana var textinn auðþekktur. Þrátt fyrir þá staðreynd að forritið er ókeypis er það almennt frábær!


4. Ályktanir
Ef þú skannar oft ekki og þekkir skjöl, þá er sennilega ekki skynsamlegt að kaupa FineReader forritið. Flest verkefni eru auðveldlega meðhöndluð af CuneiForm.
Aftur á móti hefur hún líka ókosti.
Í fyrsta lagi eru of fá tæki til að breyta og athuga niðurstöðuna. Í öðru lagi, þegar þú þarft að þekkja mikið af myndum, þá er það þægilegra í FineReader að sjá strax allt sem er bætt við verkefnið í dálkinum hér til hægri: fjarlægðu fljótt óþarfar, gerðu leiðréttingar osfrv. Og í þriðja lagi tapar CuneiForm sem viðurkenningu á skjölum: Ég verð að hafa skjalið í huga - breyta villum, setja greinarmerki, tilvitnanir o.s.frv.
Það er allt. Þekkir þú eitthvað annað verðugt forrit til að þekkja ókeypis texta?