Kveðjur til allra lesenda bloggsins!
Ég held að þeir sem oft vinna við tölvuna (spili ekki, nefnilega vinna), hafi þurft að glíma við textagögn. Jæja, til dæmis skannaðir þú útdrátt úr bók og nú þarftu að setja þennan hluta inn í skjalið þitt. En skannaða skjalið er mynd og við þurfum texta - til þess þurfum við sérstök forrit og netþjónustur til að þekkja texta úr myndum.
Um viðurkenningarforrit skrifaði ég þegar í fyrri færslum:
- textaskönnun og viðurkenningu í FineReader (greitt forrit);
- Vinna í hliðstæðum FineReader - CuneiForm (ókeypis forrit).
Í sömu grein langar mig til að dvelja við þjónustu á netinu til að þekkja texta. Þegar öllu er á botninn hvolft, ef þú þarft fljótt að fá texta með 1-2 myndum - þá er ekkert mál að nenna að setja upp ýmis forrit ...
Mikilvægt! Gæði viðurkenningar (fjöldi villna, læsileiki osfrv.) Veltur mjög á upprunalegum myndum. Þess vegna, þegar þú skannar (ljósmyndar osfrv.), Veldu gæði eins há og mögulegt er. Í flestum tilvikum nægja gæði 300-400 dpi (dpi er breytu sem einkennir myndgæði. Í stillingum næstum allra skanna er þessi færibreytur venjulega gefinn til kynna).
Netþjónusta
Til að sýna hvernig þjónustan virkar tók ég skjámynd af einni af greinunum mínum. Skjámyndinni verður hlaðið upp á alla þjónustu, lýsingin er kynnt hér að neðan.
1) //www.ocrconvert.com/

Mér þykir mjög vænt um þessa þjónustu vegna einfaldleika hennar. Þessi síða, þó enska, en virki vel með rússnesku tungumálinu. Engin þörf á að skrá sig. Til að hefja viðurkenningu þarftu að gera 3 aðgerðir:
- senda myndina þína;
- veldu tungumál textans sem er á myndinni;
- ýttu á upphafshnappinn fyrir þekkingu.
Stuðningur við snið: PDF, GIF, BMP, JPEG.
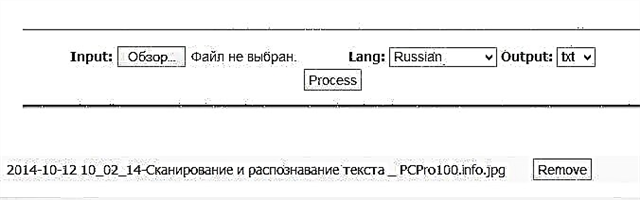
Niðurstaðan er kynnt hér að neðan á myndinni. Ég verð að segja að textinn er ágætlega viðurkenndur. Að auki mjög fljótt - ég beið bókstaflega 5-10 sekúndur.

2) //www.i2ocr.com/
Þessi þjónusta virkar á svipaðan hátt og hér að ofan. Hér þarftu einnig að hala niður skránni, velja viðurkenningartungumál og smella á hnappinn fyrir útdrátt texta. Þjónustan virkar mjög fljótt: 5-6 sekúndur. ein blaðsíða.
Styður snið: TIF, JPEG, PNG, BMP, GIF, PBM, PGM, PPM.

Árangurinn af þessari þjónustu á netinu er miklu þægilegri: þú sérð strax tvo glugga - í fyrsta, viðurkenningarniðurstaðan, í öðrum - upprunalegu myndina. Þess vegna er það auðvelt að gera breytingar þegar þú breytir. Við the vegur, það er ekki nauðsynlegt að skrá sig í þjónustuna.

3) //www.newocr.com/

Þessi þjónusta er einstök á ýmsa vegu. Í fyrsta lagi styður það „newfangled“ DJVU sniðið (við the vegur, fullur listi af sniðum: JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu). Í öðru lagi styður það val á textasvæðum á myndinni. Þetta er mjög gagnlegt þegar þú hefur ekki aðeins textasvæði á myndinni, heldur einnig grafísk svæði sem þú þarft ekki að þekkja.
Viðurkenningargæðin eru yfir meðallagi, engin þörf á að skrá sig.

4) //www.free-ocr.com/

Mjög einföld þjónusta fyrir viðurkenningu: hlaðið inn mynd, tilgreinið tungumálið, sláið inn captcha (við the vegur, eina þjónustan í þessari grein hvar á að gera þetta) og ýttu á hnappinn til að þýða myndina yfir í texta. Reyndar allt!
Studd snið: PDF, JPG, GIF, TIFF, BMP.

Viðurkenninganiðurstaðan er miðlungs. Það eru mistök, en ekki mörg. Hins vegar, ef gæði upprunalegu skjámyndarinnar voru hærri, þá væri stærðargráðu færri villna.

PS
Það er allt í dag. Ef þú þekkir áhugaverðari þjónustu fyrir textagreiningu - deildu í athugasemdunum, ég mun vera þakklátur. Eitt skilyrði: Æskilegt er að þú þurfir ekki að skrá þig og þjónustan er ókeypis.
Allt það besta!